Retrieval
Some of the concepts reviewed here utilize models to generate queries (e.g., for SQL or graph databases). There are inherent risks in doing this. Make sure that your database connection permissions are scoped as narrowly as possible for your application's needs. This will mitigate, though not eliminate, the risks of building a model-driven system capable of querying databases. For more on general security best practices, see our security guide.
Overview
Retrieval systems are fundamental to many AI applications, efficiently identifying relevant information from large datasets. These systems accommodate various data formats:
- Unstructured text (e.g., documents) is often stored in vector stores or lexical search indexes.
- Structured data is typically housed in relational or graph databases with defined schemas.
Despite the growing diversity in data formats, modern AI applications increasingly aim to make all types of data accessible through natural language interfaces. Models play a crucial role in this process by translating natural language queries into formats compatible with the underlying search index or database. This translation enables more intuitive and flexible interactions with complex data structures.
Key concepts
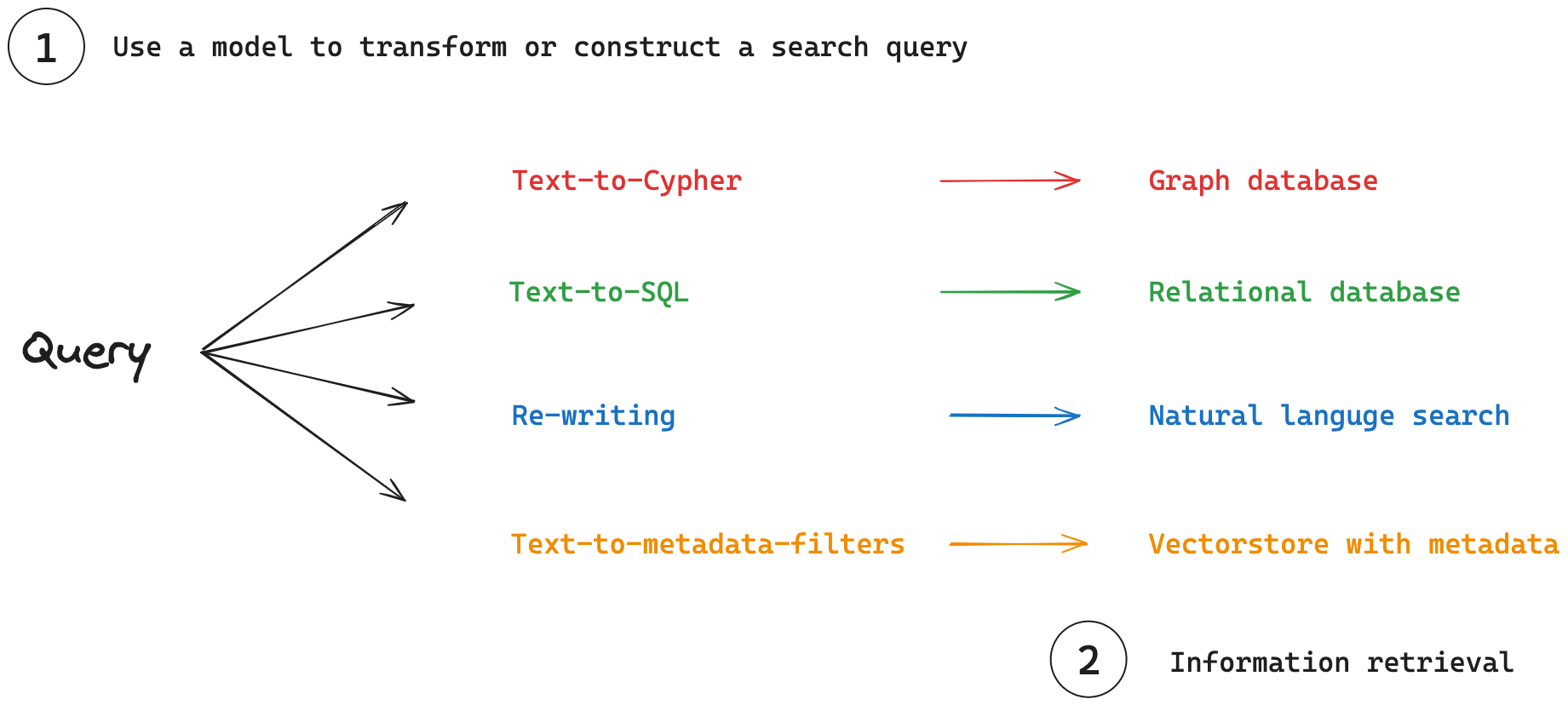
(1) Query analysis: A process where models transform or construct search queries to optimize retrieval.
(2) Information retrieval: Search queries are used to fetch information from various retrieval systems.
Query analysis
While users typically prefer to interact with retrieval systems using natural language, these systems may require specific query syntax or benefit from certain keywords. Query analysis serves as a bridge between raw user input and optimized search queries. Some common applications of query analysis include:
- Query Re-writing: Queries can be re-written or expanded to improve semantic or lexical searches.
- Query Construction: Search indexes may require structured queries (e.g., SQL for databases).
Query analysis employs models to transform or construct optimized search queries from raw user input.
Query re-writing
Retrieval systems should ideally handle a wide spectrum of user inputs, from simple and poorly worded queries to complex, multi-faceted questions. To achieve this versatility, a popular approach is to use models to transform raw user queries into more effective search queries. This transformation can range from simple keyword extraction to sophisticated query expansion and reformulation. Here are some key benefits of using models for query analysis in unstructured data retrieval:
- Query Clarification: Models can rephrase ambiguous or poorly worded queries for clarity.
- Semantic Understanding: They can capture the intent behind a query, going beyond literal keyword matching.
- Query Expansion: Models can generate related terms or concepts to broaden the search scope.
- Complex Query Handling: They can break down multi-part questions into simpler sub-queries.
Various techniques have been developed to leverage models for query re-writing, including:
| Name | When to use | Description |
|---|---|---|
| Multi-query | When you want to ensure high recall in retrieval by providing multiple phrasings of a question. | Rewrite the user question with multiple phrasings, retrieve documents for each rewritten question, return the unique documents for all queries. |
| Decomposition | When a question can be broken down into smaller subproblems. | Decompose a question into a set of subproblems / questions, which can either be solved sequentially (use the answer from first + retrieval to answer the second) or in parallel (consolidate each answer into final answer). |
| Step-back | When a higher-level conceptual understanding is required. | First prompt the LLM to ask a generic step-back question about higher-level concepts or principles, and retrieve relevant facts about them. Use this grounding to help answer the user question. Paper. |
| HyDE | If you have challenges retrieving relevant documents using the raw user inputs. | Use an LLM to convert questions into hypothetical documents that answer the question. Use the embedded hypothetical documents to retrieve real documents with the premise that doc-doc similarity search can produce more relevant matches. Paper. |
As an example, query decomposition can simply be accomplished using prompting and a structured output that enforces a list of sub-questions. These can then be run sequentially or in parallel on a downstream retrieval system.
from typing import List
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
# Define a pydantic model to enforce the output structure
class Questions(BaseModel):
questions: List[str] = Field(
description="A list of sub-questions related to the input query."
)
# Create an instance of the model and enforce the output structure
model = ChatOpenAI(model="gpt-4o", temperature=0)
structured_model = model.with_structured_output(Questions)
# Define the system prompt
system = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answered independently. \n"""
# Pass the question to the model
question = """What are the main components of an LLM-powered autonomous agent system?"""
questions = structured_model.invoke([SystemMessage(content=system)]+[HumanMessage(content=question)])
See our RAG from Scratch videos for a few different specific approaches:
Query construction
Query analysis also can focus on translating natural language queries into specialized query languages or filters. This translation is crucial for effectively interacting with various types of databases that house structured or semi-structured data.
-
Structured Data examples: For relational and graph databases, Domain-Specific Languages (DSLs) are used to query data.
- Text-to-SQL: Converts natural language to SQL for relational databases.
- Text-to-Cypher: Converts natural language to Cypher for graph databases.
-
Semi-structured Data examples: For vectorstores, queries can combine semantic search with metadata filtering.
- Natural Language to Metadata Filters: Converts user queries into appropriate metadata filters.
These approaches leverage models to bridge the gap between user intent and the specific query requirements of different data storage systems. Here are some popular techniques:
| Name | When to Use | Description |
|---|---|---|
| Self Query | If users are asking questions that are better answered by fetching documents based on metadata rather than similarity with the text. | This uses an LLM to transform user input into two things: (1) a string to look up semantically, (2) a metadata filter to go along with it. This is useful because oftentimes questions are about the METADATA of documents (not the content itself). |
| Text to SQL | If users are asking questions that require information housed in a relational database, accessible via SQL. | This uses an LLM to transform user input into a SQL query. |
| Text-to-Cypher | If users are asking questions that require information housed in a graph database, accessible via Cypher. | This uses an LLM to transform user input into a Cypher query. |
As an example, here is how to use the SelfQueryRetriever to convert natural language queries into metadata filters.
metadata_field_info = schema_for_metadata
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
- See our tutorials on text-to-SQL, text-to-Cypher, and query analysis for metadata filters.
- See our blog post overview.
- See our RAG from Scratch video on query construction.
Information retrieval
Common retrieval systems
Lexical search indexes
Many search engines are based upon matching words in a query to the words in each document. This approach is called lexical retrieval, using search algorithms that are typically based upon word frequencies. The intution is simple: a word appears frequently both in the user’s query and a particular document, then this document might be a good match.
The particular data structure used to implement this is often an inverted index. This types of index contains a list of words and a mapping of each word to a list of locations at which it occurs in various documents. Using this data structure, it is possible to efficiently match the words in search queries to the documents in which they appear. BM25 and TF-IDF are two popular lexical search algorithms.
- See the BM25 retriever integration.
- See the Elasticsearch retriever integration.
Vector indexes
Vector indexes are an alternative way to index and store unstructured data. See our conceptual guide on vectorstores for a detailed overview. In short, rather than using word frequencies, vectorstores use an embedding model to compress documents into high-dimensional vector representation. This allows for efficient similarity search over embedding vectors using simple mathematical operations like cosine similarity.
- See our how-to guide for more details on working with vectorstores.
- See our list of vectorstore integrations.
- See Cameron Wolfe's blog post on the basics of vector search.
Relational databases
Relational databases are a fundamental type of structured data storage used in many applications. They organize data into tables with predefined schemas, where each table represents an entity or relationship. Data is stored in rows (records) and columns (attributes), allowing for efficient querying and manipulation through SQL (Structured Query Language). Relational databases excel at maintaining data integrity, supporting complex queries, and handling relationships between different data entities.
- See our tutorial for working with SQL databases.
- See our SQL database toolkit.
Graph databases
Graph databases are a specialized type of database designed to store and manage highly interconnected data. Unlike traditional relational databases, graph databases use a flexible structure consisting of nodes (entities), edges (relationships), and properties. This structure allows for efficient representation and querying of complex, interconnected data. Graph databases store data in a graph structure, with nodes, edges, and properties. They are particularly useful for storing and querying complex relationships between data points, such as social networks, supply-chain management, fraud detection, and recommendation services
- See our tutorial for working with graph databases.
- See our list of graph database integrations.
- See Neo4j's starter kit for LangChain.
Retriever
LangChain provides a unified interface for interacting with various retrieval systems through the retriever concept. The interface is straightforward:
- Input: A query (string)
- Output: A list of documents (standardized LangChain Document objects)
You can create a retriever using any of the retrieval systems mentioned earlier. The query analysis techniques we discussed are particularly useful here, as they enable natural language interfaces for databases that typically require structured query languages.
For example, you can build a retriever for a SQL database using text-to-SQL conversion. This allows a natural language query (string) to be transformed into a SQL query behind the scenes.
Regardless of the underlying retrieval system, all retrievers in LangChain share a common interface. You can use them with the simple invoke method:
docs = retriever.invoke(query)
- See our conceptual guide on retrievers.
- See our how-to guide on working with retrievers.