Retrievers
Overview
Many different types of retrieval systems exist, including vectorstores, graph databases, and relational databases. With the rise on popularity of large language models, retrieval systems have become an important component in AI application (e.g., RAG). Because of their importance and variability, LangChain provides a uniform interface for interacting with different types of retrieval systems. The LangChain retriever interface is straightforward:
- Input: A query (string)
- Output: A list of documents (standardized LangChain Document objects)
Key concept
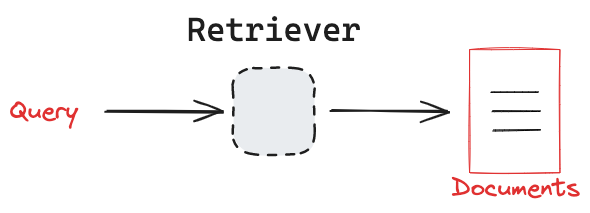
All retrievers implement a simple interface for retrieving documents using natural language queries.
Interface
The only requirement for a retriever is the ability to accepts a query and return documents.
In particular, LangChain's retriever class only requires that the _get_relevant_documents method is implemented, which takes a query: str and returns a list of Document objects that are most relevant to the query.
The underlying logic used to get relevant documents is specified by the retriever and can be whatever is most useful for the application.
A LangChain retriever is a runnable, which is a standard interface for LangChain components.
This means that it has a few common methods, including invoke, that are used to interact with it. A retriever can be invoked with a query:
docs = retriever.invoke(query)
Retrievers return a list of Document objects, which have two attributes:
page_content: The content of this document. Currently is a string.metadata: Arbitrary metadata associated with this document (e.g., document id, file name, source, etc).
- See our how-to guide on building your own custom retriever.
Common types
Despite the flexibility of the retriever interface, a few common types of retrieval systems are frequently used.
Search apis
It's important to note that retrievers don't need to actually store documents. For example, we can build retrievers on top of search APIs that simply return search results! See our retriever integrations with Amazon Kendra or Wikipedia Search.
Relational or graph database
Retrievers can be built on top of relational or graph databases. In these cases, query analysis techniques to construct a structured query from natural language is critical. For example, you can build a retriever for a SQL database using text-to-SQL conversion. This allows a natural language query (string) retriever to be transformed into a SQL query behind the scenes.
Lexical search
As discussed in our conceptual review of retrieval, many search engines are based upon matching words in a query to the words in each document. BM25 and TF-IDF are two popular lexical search algorithms. LangChain has retrievers for many popular lexical search algorithms / engines.
- See the BM25 retriever integration.
- See the TF-IDF retriever integration.
- See the Elasticsearch retriever integration.
Vector store
Vector stores are a powerful and efficient way to index and retrieve unstructured data.
A vectorstore can be used as a retriever by calling the as_retriever() method.
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
Advanced retrieval patterns
Ensemble
Because the retriever interface is so simple, returning a list of Document objects given a search query, it is possible to combine multiple retrievers using ensembling.
This is particularly useful when you have multiple retrievers that are good at finding different types of relevant documents.
It is easy to create an ensemble retriever that combines multiple retrievers with linear weighted scores:
# Initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_store_retriever], weights=[0.5, 0.5]
)
When ensembling, how do we combine search results from many retrievers? This motivates the concept of re-ranking, which takes the output of multiple retrievers and combines them using a more sophisticated algorithm such as Reciprocal Rank Fusion (RRF).
Source document retention
Many retrievers utilize some kind of index to make documents easily searchable. The process of indexing can include a transformation step (e.g., vectorstores often use document splitting). Whatever transformation is used, can be very useful to retain a link between the transformed document and the original, giving the retriever the ability to return the original document.
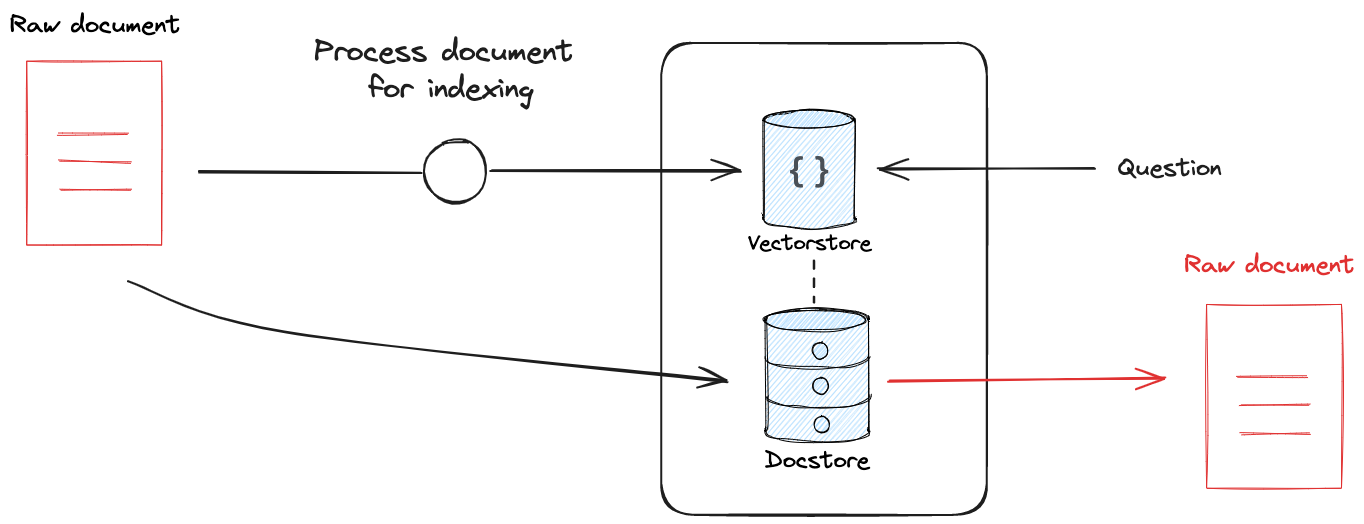
This is particularly useful in AI applications, because it ensures no loss in document context for the model. For example, you may use small chunk size for indexing documents in a vectorstore. If you return only the chunks as the retrieval result, then the model will have lost the original document context for the chunks.
LangChain has two different retrievers that can be used to address this challenge. The Multi-Vector retriever allows the user to use any document transformation (e.g., use an LLM to write a summary of the document) for indexing while retaining linkage to the source document. The ParentDocument retriever links document chunks from a text-splitter transformation for indexing while retaining linkage to the source document.
| Name | Index Type | Uses an LLM | When to Use | Description |
|---|---|---|---|---|
| ParentDocument | Vector store + Document Store | No | If your pages have lots of smaller pieces of distinct information that are best indexed by themselves, but best retrieved all together. | This involves indexing multiple chunks for each document. Then you find the chunks that are most similar in embedding space, but you retrieve the whole parent document and return that (rather than individual chunks). |
| Multi Vector | Vector store + Document Store | Sometimes during indexing | If you are able to extract information from documents that you think is more relevant to index than the text itself. | This involves creating multiple vectors for each document. Each vector could be created in a myriad of ways - examples include summaries of the text and hypothetical questions. |
- See our how-to guide on using the ParentDocument retriever.
- See our how-to guide on using the MultiVector retriever.
- See our RAG from Scratch video on the multi vector retriever.