Run models locally
Use case
The popularity of projects like llama.cpp, Ollama, GPT4All, llamafile, and others underscore the demand to run LLMs locally (on your own device).
This has at least two important benefits:
- Privacy: Your data is not sent to a third party, and it is not subject to the terms of service of a commercial service
- Cost: There is no inference fee, which is important for token-intensive applications (e.g., long-running simulations, summarization)
Overview
Running an LLM locally requires a few things:
- Open-source LLM: An open-source LLM that can be freely modified and shared
- Inference: Ability to run this LLM on your device w/ acceptable latency
Open-source LLMs
Users can now gain access to a rapidly growing set of open-source LLMs.
These LLMs can be assessed across at least two dimensions (see figure):
- Base model: What is the base-model and how was it trained?
- Fine-tuning approach: Was the base-model fine-tuned and, if so, what set of instructions was used?
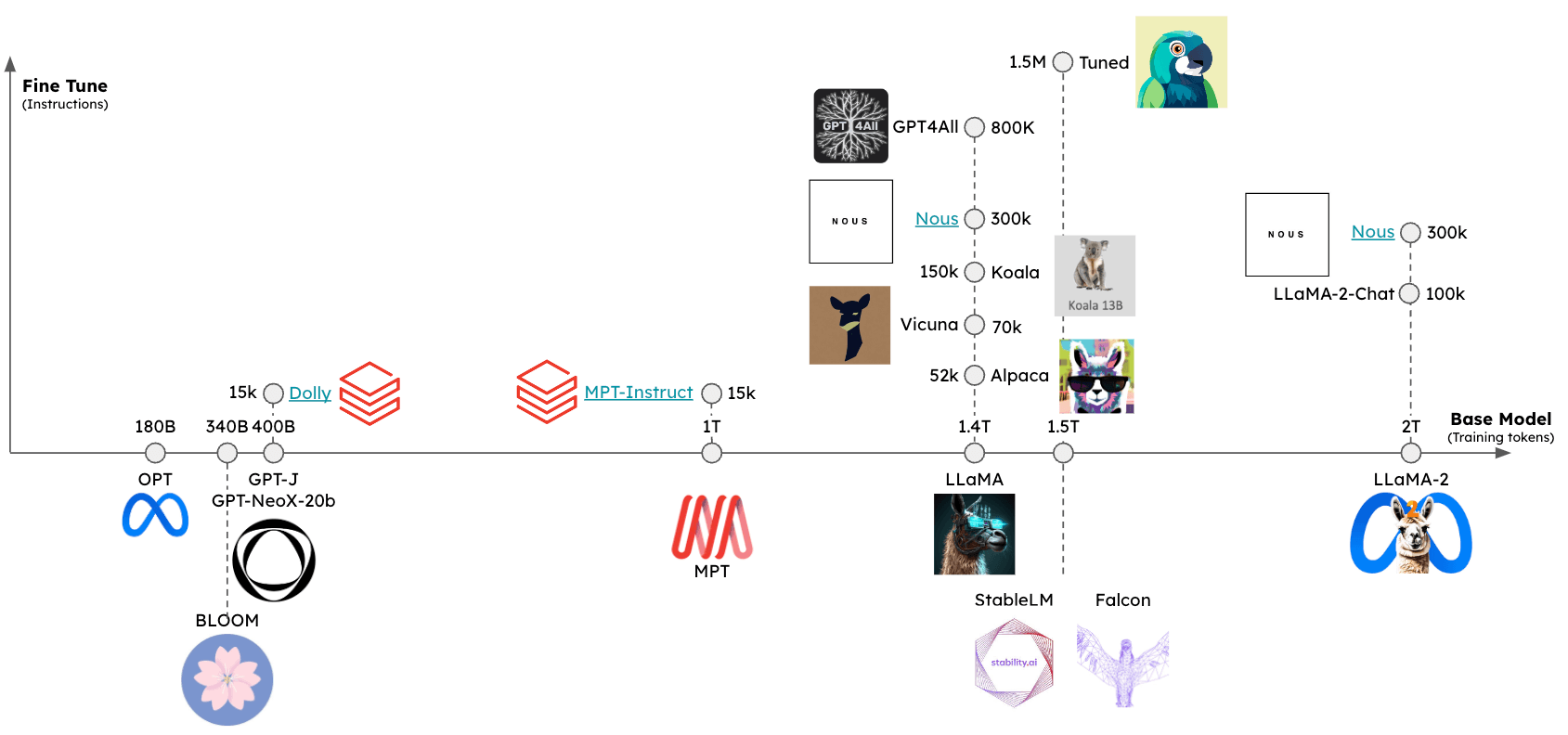
The relative performance of these models can be assessed using several leaderboards, including:
Inference
A few frameworks for this have emerged to support inference of open-source LLMs on various devices:
llama.cpp: C++ implementation of llama inference code with weight optimization / quantizationgpt4all: Optimized C backend for inferenceollama: Bundles model weights and environment into an app that runs on device and serves the LLMllamafile: Bundles model weights and everything needed to run the model in a single file, allowing you to run the LLM locally from this file without any additional installation steps
In general, these frameworks will do a few things:
- Quantization: Reduce the memory footprint of the raw model weights
- Efficient implementation for inference: Support inference on consumer hardware (e.g., CPU or laptop GPU)
In particular, see this excellent post on the importance of quantization.
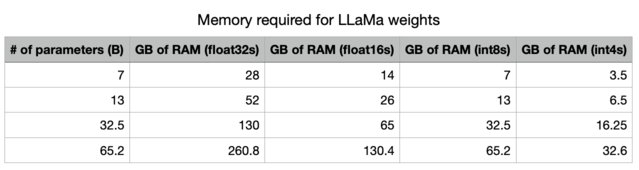
With less precision, we radically decrease the memory needed to store the LLM in memory.
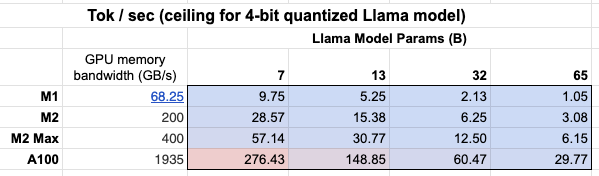
In addition, we can see the importance of GPU memory bandwidth sheet!
A Mac M2 Max is 5-6x faster than a M1 for inference due to the larger GPU memory bandwidth.
Formatting prompts
Some providers have chat model wrappers that takes care of formatting your input prompt for the specific local model you're using. However, if you are prompting local models with a text-in/text-out LLM wrapper, you may need to use a prompt tailored for your specific model.
This can require the inclusion of special tokens. Here's an example for LLaMA 2.
Quickstart
Ollama is one way to easily run inference on macOS.
The instructions here provide details, which we summarize:
- Download and run the app
- From command line, fetch a model from this list of options: e.g.,
ollama pull gpt-oss:20b - When the app is running, all models are automatically served on
localhost:11434
%pip install -qU langchain_ollama
from langchain_ollama import ChatOllama
llm = ChatOllama(model="gpt-oss:20b", validate_model_on_init=True)
llm.invoke("The first man on the moon was ...").content
'...Neil Armstrong!\n\nOn July 20, 1969, Neil Armstrong became the first person to set foot on the lunar surface, famously declaring "That\'s one small step for man, one giant leap for mankind" as he stepped off the lunar module Eagle onto the Moon\'s surface.\n\nWould you like to know more about the Apollo 11 mission or Neil Armstrong\'s achievements?'
Stream tokens as they are being generated:
for chunk in llm.stream("The first man on the moon was ..."):
print(chunk, end="|", flush=True)
...|
``````output
Neil| Armstrong|,| an| American| astronaut|.| He| stepped| out| of| the| lunar| module| Eagle| and| onto| the| surface| of| the| Moon| on| July| |20|,| |196|9|,| famously| declaring|:| "|That|'s| one| small| step| for| man|,| one| giant| leap| for| mankind|."||
Ollama also includes a chat model wrapper that handles formatting conversation turns:
from langchain_ollama import ChatOllama
chat_model = ChatOllama(model="llama3.1:8b")
chat_model.invoke("Who was the first man on the moon?")
AIMessage(content='The answer is a historic one!\n\nThe first man to walk on the Moon was Neil Armstrong, an American astronaut and commander of the Apollo 11 mission. On July 20, 1969, Armstrong stepped out of the lunar module Eagle onto the surface of the Moon, famously declaring:\n\n"That\'s one small step for man, one giant leap for mankind."\n\nArmstrong was followed by fellow astronaut Edwin "Buzz" Aldrin, who also walked on the Moon during the mission. Michael Collins remained in orbit around the Moon in the command module Columbia.\n\nNeil Armstrong passed away on August 25, 2012, but his legacy as a pioneering astronaut and engineer continues to inspire people around the world!', response_metadata={'model': 'llama3.1:8b', 'created_at': '2024-08-01T00:38:29.176717Z', 'message': {'role': 'assistant', 'content': ''}, 'done_reason': 'stop', 'done': True, 'total_duration': 10681861417, 'load_duration': 34270292, 'prompt_eval_count': 19, 'prompt_eval_duration': 6209448000, 'eval_count': 141, 'eval_duration': 4432022000}, id='run-7bed57c5-7f54-4092-912c-ae49073dcd48-0', usage_metadata={'input_tokens': 19, 'output_tokens': 141, 'total_tokens': 160})
Environment
Inference speed is a challenge when running models locally (see above).
To minimize latency, it is desirable to run models locally on GPU, which ships with many consumer laptops e.g., Apple devices.
And even with GPU, the available GPU memory bandwidth (as noted above) is important.
Running Apple silicon GPU
ollama and llamafile will automatically utilize the GPU on Apple devices.
Other frameworks require the user to set up the environment to utilize the Apple GPU.
For example, llama.cpp python bindings can be configured to use the GPU via Metal.
Metal is a graphics and compute API created by Apple providing near-direct access to the GPU.
See the llama.cpp setup here to enable this.
In particular, ensure that conda is using the correct virtual environment that you created (miniforge3).
e.g., for me:
conda activate /Users/rlm/miniforge3/envs/llama
With the above confirmed, then:
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
LLMs
There are various ways to gain access to quantized model weights.
HuggingFace- Many quantized model are available for download and can be run with framework such asllama.cpp. You can also download models inllamafileformat from HuggingFace.gpt4all- The model explorer offers a leaderboard of metrics and associated quantized models available for downloadollama- Several models can be accessed directly viapull
Ollama�
With Ollama, fetch a model via ollama pull <model family>:<tag>.
llm = ChatOllama(model="gpt-oss:20b")
llm.invoke("The first man on the moon was ... think step by step")
' Sure! Here\'s the answer, broken down step by step:\n\nThe first man on the moon was... Neil Armstrong.\n\nHere\'s how I arrived at that answer:\n\n1. The first manned mission to land on the moon was Apollo 11.\n2. The mission included three astronauts: Neil Armstrong, Edwin "Buzz" Aldrin, and Michael Collins.\n3. Neil Armstrong was the mission commander and the first person to set foot on the moon.\n4. On July 20, 1969, Armstrong stepped out of the lunar module Eagle and onto the moon\'s surface, famously declaring "That\'s one small step for man, one giant leap for mankind."\n\nSo, the first man on the moon was Neil Armstrong!'
Llama.cpp
Llama.cpp is compatible with a broad set of models.
For example, below we run inference on llama2-13b with 4 bit quantization downloaded from HuggingFace.
As noted above, see the API reference for the full set of parameters.
From the llama.cpp API reference docs, a few are worth commenting on:
n_gpu_layers: number of layers to be loaded into GPU memory
- Value: 1
- Meaning: Only one layer of the model will be loaded into GPU memory (1 is often sufficient).
n_batch: number of tokens the model should process in parallel
- Value: n_batch
- Meaning: It's recommended to choose a value between 1 and n_ctx (which in this case is set to 2048)
n_ctx: Token context window
- Value: 2048
- Meaning: The model will consider a window of 2048 tokens at a time
f16_kv: whether the model should use half-precision for the key/value cache
- Value: True
- Meaning: The model will use half-precision, which can be more memory efficient; Metal only supports True.
%env CMAKE_ARGS="-DLLAMA_METAL=on"
%env FORCE_CMAKE=1
%pip install --upgrade --quiet llama-cpp-python --no-cache-dir
from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/openorca-platypus2-13b.gguf.q4_0.bin",
n_gpu_layers=1,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)
The console log will show the below to indicate Metal was enabled properly from steps above:
ggml_metal_init: allocating
ggml_metal_init: using MPS
llm.invoke("The first man on the moon was ... Let's think step by step")
Llama.generate: prefix-match hit
``````output
and use logical reasoning to figure out who the first man on the moon was.
Here are some clues:
1. The first man on the moon was an American.
2. He was part of the Apollo 11 mission.
3. He stepped out of the lunar module and became the first person to set foot on the moon's surface.
4. His last name is Armstrong.
Now, let's use our reasoning skills to figure out who the first man on the moon was. Based on clue #1, we know that the first man on the moon was an American. Clue #2 tells us that he was part of the Apollo 11 mission. Clue #3 reveals that he was the first person to set foot on the moon's surface. And finally, clue #4 gives us his last name: Armstrong.
Therefore, the first man on the moon was Neil Armstrong!
``````output
llama_print_timings: load time = 9623.21 ms
llama_print_timings: sample time = 143.77 ms / 203 runs ( 0.71 ms per token, 1412.01 tokens per second)
llama_print_timings: prompt eval time = 485.94 ms / 7 tokens ( 69.42 ms per token, 14.40 tokens per second)
llama_print_timings: eval time = 6385.16 ms / 202 runs ( 31.61 ms per token, 31.64 tokens per second)
llama_print_timings: total time = 7279.28 ms
" and use logical reasoning to figure out who the first man on the moon was.\n\nHere are some clues:\n\n1. The first man on the moon was an American.\n2. He was part of the Apollo 11 mission.\n3. He stepped out of the lunar module and became the first person to set foot on the moon's surface.\n4. His last name is Armstrong.\n\nNow, let's use our reasoning skills to figure out who the first man on the moon was. Based on clue #1, we know that the first man on the moon was an American. Clue #2 tells us that he was part of the Apollo 11 mission. Clue #3 reveals that he was the first person to set foot on the moon's surface. And finally, clue #4 gives us his last name: Armstrong.\nTherefore, the first man on the moon was Neil Armstrong!"
GPT4All
We can use model weights downloaded from GPT4All model explorer.
Similar to what is shown above, we can run inference and use the API reference to set parameters of interest.
%pip install gpt4all
from langchain_community.llms import GPT4All
llm = GPT4All(
model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin"
)
llm.invoke("The first man on the moon was ... Let's think step by step")
".\n1) The United States decides to send a manned mission to the moon.2) They choose their best astronauts and train them for this specific mission.3) They build a spacecraft that can take humans to the moon, called the Lunar Module (LM).4) They also create a larger spacecraft, called the Saturn V rocket, which will launch both the LM and the Command Service Module (CSM), which will carry the astronauts into orbit.5) The mission is planned down to the smallest detail: from the trajectory of the rockets to the exact movements of the astronauts during their moon landing.6) On July 16, 1969, the Saturn V rocket launches from Kennedy Space Center in Florida, carrying the Apollo 11 mission crew into space.7) After one and a half orbits around the Earth, the LM separates from the CSM and begins its descent to the moon's surface.8) On July 20, 1969, at 2:56 pm EDT (GMT-4), Neil Armstrong becomes the first man on the moon. He speaks these"
llamafile
One of the simplest ways to run an LLM locally is using a llamafile. All you need to do is:
- Download a llamafile from HuggingFace
- Make the file executable
- Run the file
llamafiles bundle model weights and a specially-compiled version of llama.cpp into a single file that can run on most computers without any additional dependencies. They also come with an embedded inference server that provides an API for interacting with your model.
Here's a simple bash script that shows all 3 setup steps:
# Download a llamafile from HuggingFace
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Make the file executable. On Windows, instead just rename the file to end in ".exe".
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# Start the model server. Listens at http://localhost:8080 by default.
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser
After you run the above setup steps, you can use LangChain to interact with your model:
from langchain_community.llms.llamafile import Llamafile
llm = Llamafile()
llm.invoke("The first man on the moon was ... Let's think step by step.")
"\nFirstly, let's imagine the scene where Neil Armstrong stepped onto the moon. This happened in 1969. The first man on the moon was Neil Armstrong. We already know that.\n2nd, let's take a step back. Neil Armstrong didn't have any special powers. He had to land his spacecraft safely on the moon without injuring anyone or causing any damage. If he failed to do this, he would have been killed along with all those people who were on board the spacecraft.\n3rd, let's imagine that Neil Armstrong successfully landed his spacecraft on the moon and made it back to Earth safely. The next step was for him to be hailed as a hero by his people back home. It took years before Neil Armstrong became an American hero.\n4th, let's take another step back. Let's imagine that Neil Armstrong wasn't hailed as a hero, and instead, he was just forgotten. This happened in the 1970s. Neil Armstrong wasn't recognized for his remarkable achievement on the moon until after he died.\n5th, let's take another step back. Let's imagine that Neil Armstrong didn't die in the 1970s and instead, lived to be a hundred years old. This happened in 2036. In the year 2036, Neil Armstrong would have been a centenarian.\nNow, let's think about the present. Neil Armstrong is still alive. He turned 95 years old on July 20th, 2018. If he were to die now, his achievement of becoming the first human being to set foot on the moon would remain an unforgettable moment in history.\nI hope this helps you understand the significance and importance of Neil Armstrong's achievement on the moon!"
Prompts
Some LLMs will benefit from specific prompts.
For example, LLaMA will use special tokens.
We can use ConditionalPromptSelector to set prompt based on the model type.
# Set our LLM
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/openorca-platypus2-13b.gguf.q4_0.bin",
n_gpu_layers=1,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)
Set the associated prompt based upon the model version.
from langchain.chains.prompt_selector import ConditionalPromptSelector
from langchain_core.prompts import PromptTemplate
DEFAULT_LLAMA_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""<<SYS>> \n You are an assistant tasked with improving Google search \
results. \n <</SYS>> \n\n [INST] Generate THREE Google search queries that \
are similar to this question. The output should be a numbered list of questions \
and each should have a question mark at the end: \n\n {question} [/INST]""",
)
DEFAULT_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an assistant tasked with improving Google search \
results. Generate THREE Google search queries that are similar to \
this question. The output should be a numbered list of questions and each \
should have a question mark at the end: {question}""",
)
QUESTION_PROMPT_SELECTOR = ConditionalPromptSelector(
default_prompt=DEFAULT_SEARCH_PROMPT,
conditionals=[(lambda llm: isinstance(llm, LlamaCpp), DEFAULT_LLAMA_SEARCH_PROMPT)],
)
prompt = QUESTION_PROMPT_SELECTOR.get_prompt(llm)
prompt
PromptTemplate(input_variables=['question'], output_parser=None, partial_variables={}, template='<<SYS>> \n You are an assistant tasked with improving Google search results. \n <</SYS>> \n\n [INST] Generate THREE Google search queries that are similar to this question. The output should be a numbered list of questions and each should have a question mark at the end: \n\n {question} [/INST]', template_format='f-string', validate_template=True)
# Chain
chain = prompt | llm
question = "What NFL team won the Super Bowl in the year that Justin Bieber was born?"
chain.invoke({"question": question})
Sure! Here are three similar search queries with a question mark at the end:
1. Which NBA team did LeBron James lead to a championship in the year he was drafted?
2. Who won the Grammy Awards for Best New Artist and Best Female Pop Vocal Performance in the same year that Lady Gaga was born?
3. What MLB team did Babe Ruth play for when he hit 60 home runs in a single season?
``````output
llama_print_timings: load time = 14943.19 ms
llama_print_timings: sample time = 72.93 ms / 101 runs ( 0.72 ms per token, 1384.87 tokens per second)
llama_print_timings: prompt eval time = 14942.95 ms / 93 tokens ( 160.68 ms per token, 6.22 tokens per second)
llama_print_timings: eval time = 3430.85 ms / 100 runs ( 34.31 ms per token, 29.15 tokens per second)
llama_print_timings: total time = 18578.26 ms
' Sure! Here are three similar search queries with a question mark at the end:\n\n1. Which NBA team did LeBron James lead to a championship in the year he was drafted?\n2. Who won the Grammy Awards for Best New Artist and Best Female Pop Vocal Performance in the same year that Lady Gaga was born?\n3. What MLB team did Babe Ruth play for when he hit 60 home runs in a single season?'
We also can use the LangChain Prompt Hub to fetch and / or store prompts that are model specific.
This will work with your LangSmith API key.
For example, here is a prompt for RAG with LLaMA-specific tokens.
Use cases
Given an llm created from one of the models above, you can use it for many use cases.
For example, you can implement a RAG application using the chat models demonstrated here.
In general, use cases for local LLMs can be driven by at least two factors:
- Privacy: private data (e.g., journals, etc) that a user does not want to share
- Cost: text preprocessing (extraction/tagging), summarization, and agent simulations are token-use-intensive tasks
In addition, here is an overview on fine-tuning, which can utilize open-source LLMs.