Portkey
Portkey is the Control Panel for AI apps. With it's popular AI Gateway and Observability Suite, hundreds of teams ship reliable, cost-efficient, and fast apps.
LLMOps for Langchain
Portkey brings production readiness to Langchain. With Portkey, you can
- Connect to 150+ models through a unified API,
- View 42+ metrics & logs for all requests,
- Enable semantic cache to reduce latency & costs,
- Implement automatic retries & fallbacks for failed requests,
- Add custom tags to requests for better tracking and analysis and more.
Quickstart - Portkey & Langchain
Since Portkey is fully compatible with the OpenAI signature, you can connect to the Portkey AI Gateway through the ChatOpenAI interface.
- Set the
base_urlasPORTKEY_GATEWAY_URL - Add
default_headersto consume the headers needed by Portkey using thecreateHeadershelper method.
To start, get your Portkey API key by signing up here. (Click the profile icon on the bottom left, then click on "Copy API Key") or deploy the open source AI gateway in your own environment.
Next, install the Portkey SDK
pip install -U portkey_ai
We can now connect to the Portkey AI Gateway by updating the ChatOpenAI model in Langchain
from langchain_openai import ChatOpenAI
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
PORTKEY_API_KEY = "..." # Not needed when hosting your own gateway
PROVIDER_API_KEY = "..." # Add the API key of the AI provider being used
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY,provider="openai")
llm = ChatOpenAI(api_key=PROVIDER_API_KEY, base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers)
llm.invoke("What is the meaning of life, universe and everything?")
The request is routed through your Portkey AI Gateway to the specified provider. Portkey will also start logging all the requests in your account that makes debugging extremely simple.
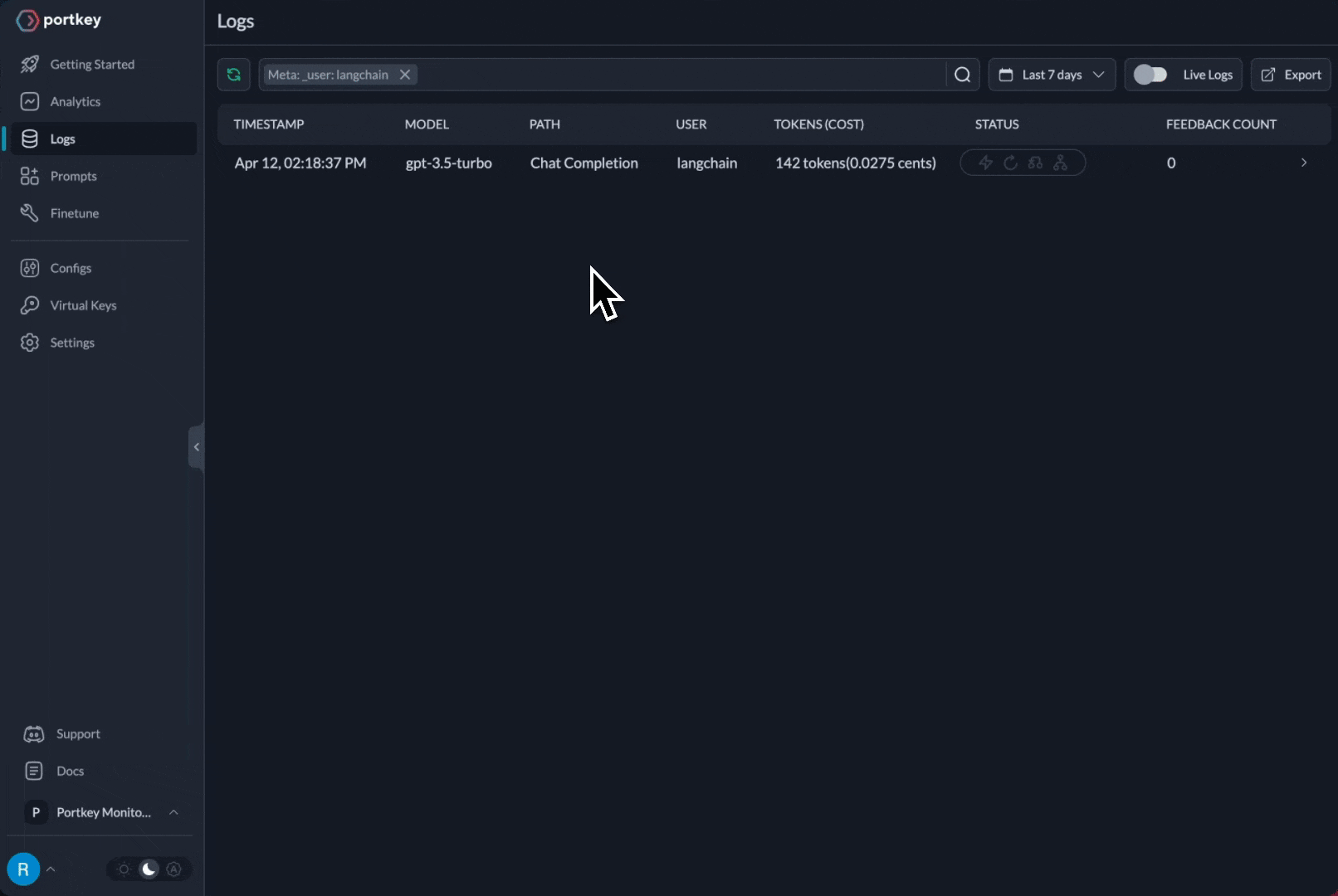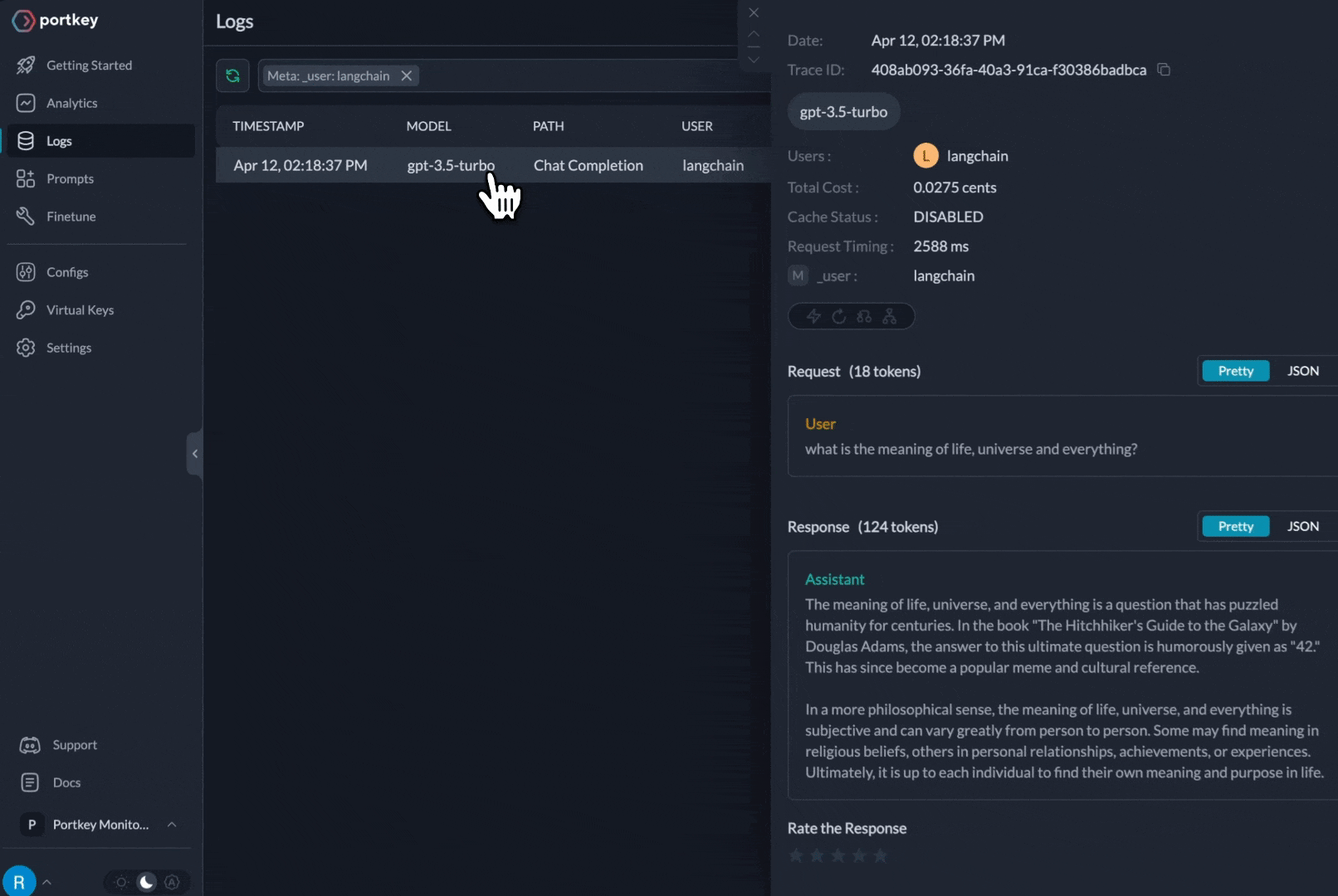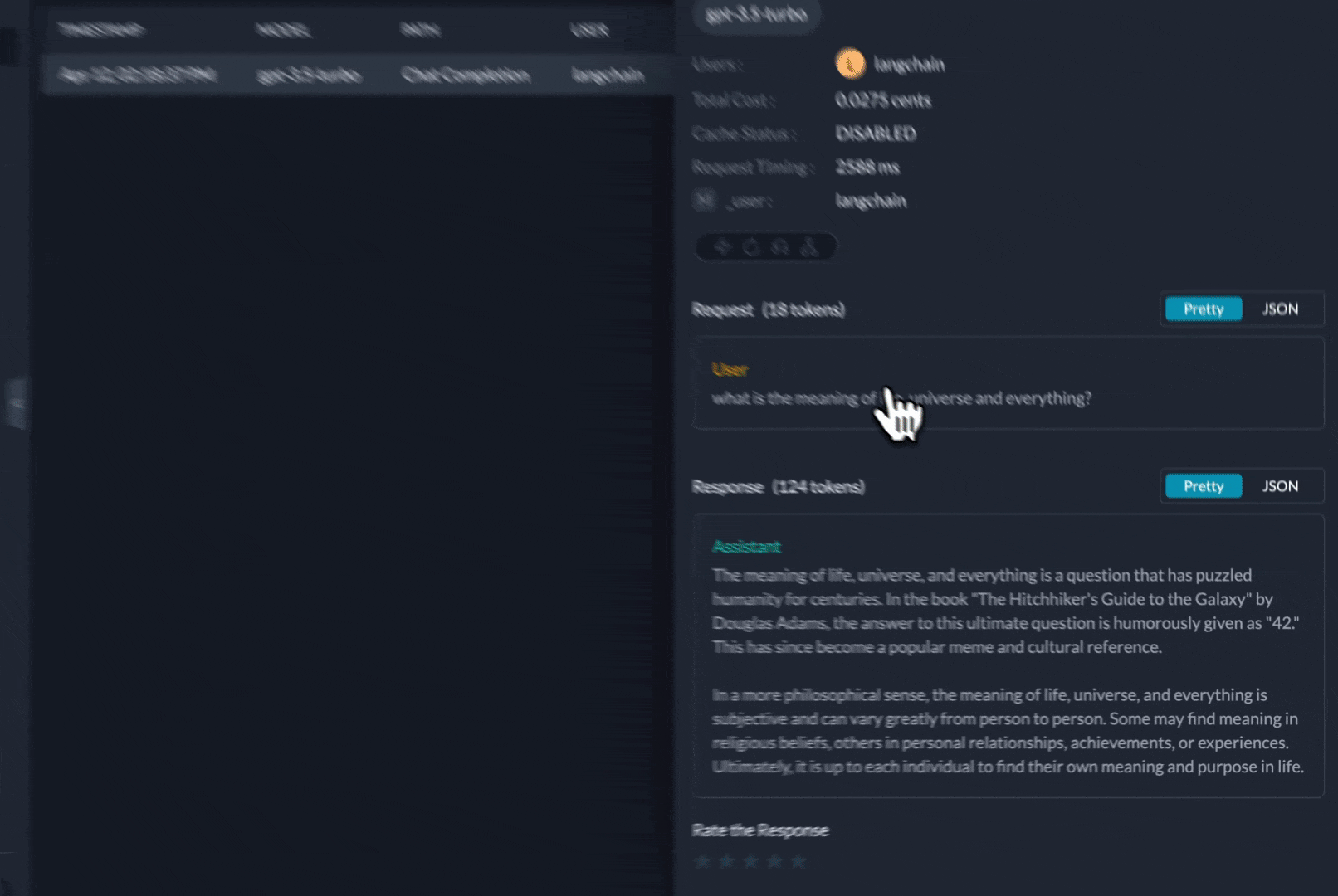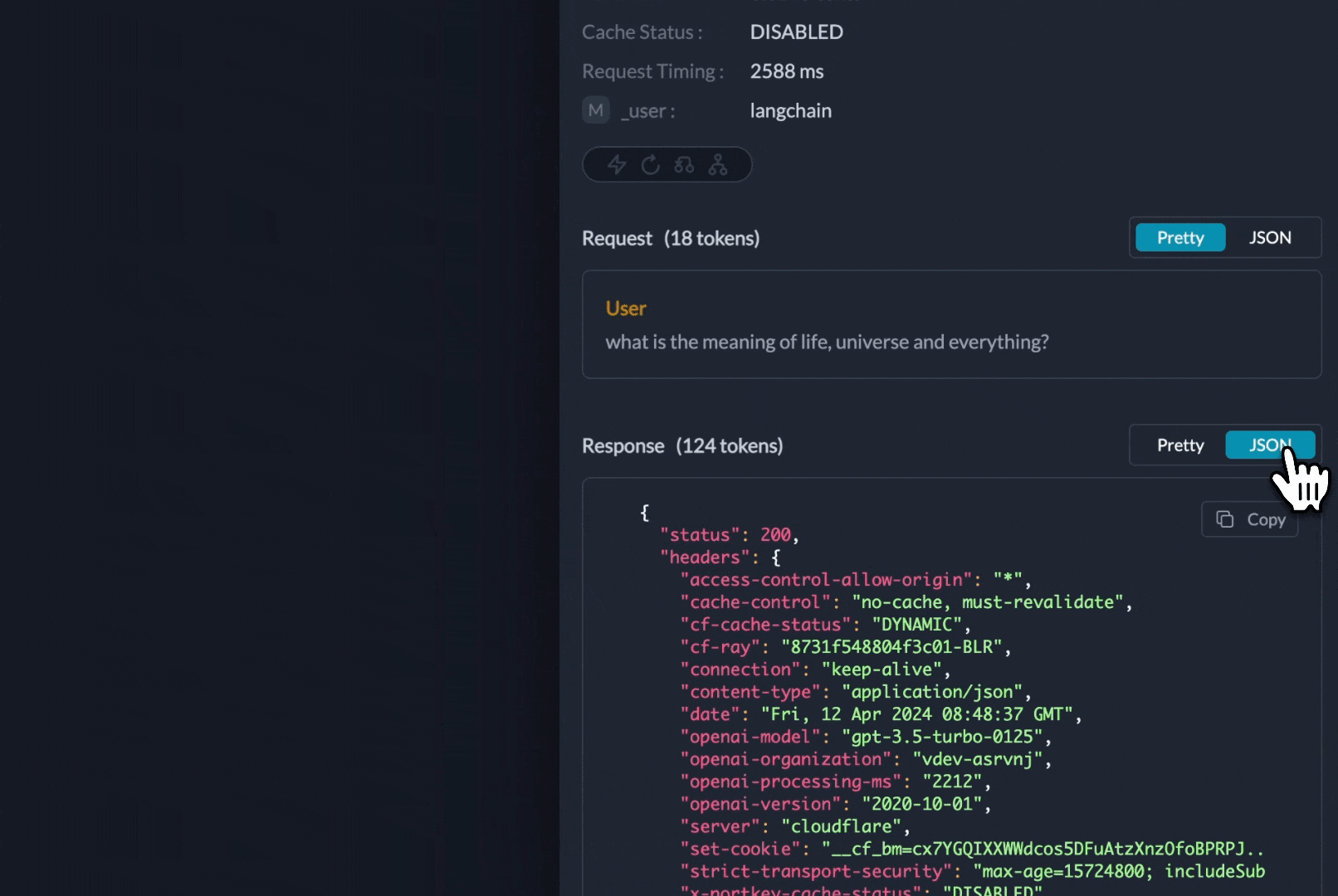
Using 150+ models through the AI Gateway
The power of the AI gateway comes when you're able to use the above code snippet to connect with 150+ models across 20+ providers supported through the AI gateway.
Let's modify the code above to make a call to Anthropic's claude-3-opus-20240229 model.
Portkey supports Virtual Keys which are an easy way to store and manage API keys in a secure vault. Let's try using a Virtual Key to make LLM calls. You can navigate to the Virtual Keys tab in Portkey and create a new key for Anthropic.
The virtual_key parameter sets the authentication and provider for the AI provider being used. In our case we're using the Anthropic Virtual key.
Notice that the
api_keycan be left blank as that authentication won't be used.
from langchain_openai import ChatOpenAI
from portkey_ai import createHeaders, PORTKEY_GATEWAY_URL
PORTKEY_API_KEY = "..."
VIRTUAL_KEY = "..." # Anthropic's virtual key we copied above
portkey_headers = createHeaders(api_key=PORTKEY_API_KEY,virtual_key=VIRTUAL_KEY)
llm = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, model="claude-3-opus-20240229")
llm.invoke("What is the meaning of life, universe and everything?")
The Portkey AI gateway will authenticate the API request to Anthropic and get the response back in the OpenAI format for you to consume.
The AI gateway extends Langchain's ChatOpenAI class making it a single interface to call any provider and any model.
Advanced Routing - Load Balancing, Fallbacks, Retries
The Portkey AI Gateway brings capabilities like load-balancing, fallbacks, experimentation and canary testing to Langchain through a configuration-first approach.
Let's take an example where we might want to split traffic between gpt-4 and claude-opus 50:50 to test the two large models. The gateway configuration for this would look like the following:
config = {
"strategy": {
"mode": "loadbalance"
},
"targets": [{
"virtual_key": "openai-25654", # OpenAI's virtual key
"override_params": {"model": "gpt4"},
"weight": 0.5
}, {
"virtual_key": "anthropic-25654", # Anthropic's virtual key
"override_params": {"model": "claude-3-opus-20240229"},
"weight": 0.5
}]
}
We can then use this config in our requests being made from langchain.
portkey_headers = createHeaders(
api_key=PORTKEY_API_KEY,
config=config
)
llm = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers)
llm.invoke("What is the meaning of life, universe and everything?")
When the LLM is invoked, Portkey will distribute the requests to gpt-4 and claude-3-opus-20240229 in the ratio of the defined weights.
You can find more config examples here.
Tracing Chains & Agents
Portkey's Langchain integration gives you full visibility into the running of an agent. Let's take an example of a popular agentic workflow.
We only need to modify the ChatOpenAI class to use the AI Gateway as above.
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
prompt = hub.pull("hwchase17/openai-tools-agent")
portkey_headers = createHeaders(
api_key=PORTKEY_API_KEY,
virtual_key=OPENAI_VIRTUAL_KEY,
trace_id="uuid-uuid-uuid-uuid"
)
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
tools = [multiply, exponentiate]
model = ChatOpenAI(api_key="X", base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, temperature=0)
# Construct the OpenAI Tools agent
agent = create_openai_tools_agent(model, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({
"input": "Take 3 to the fifth power and multiply that by thirty six, then square the result"
})
You can see the requests' logs along with the trace id on Portkey dashboard:
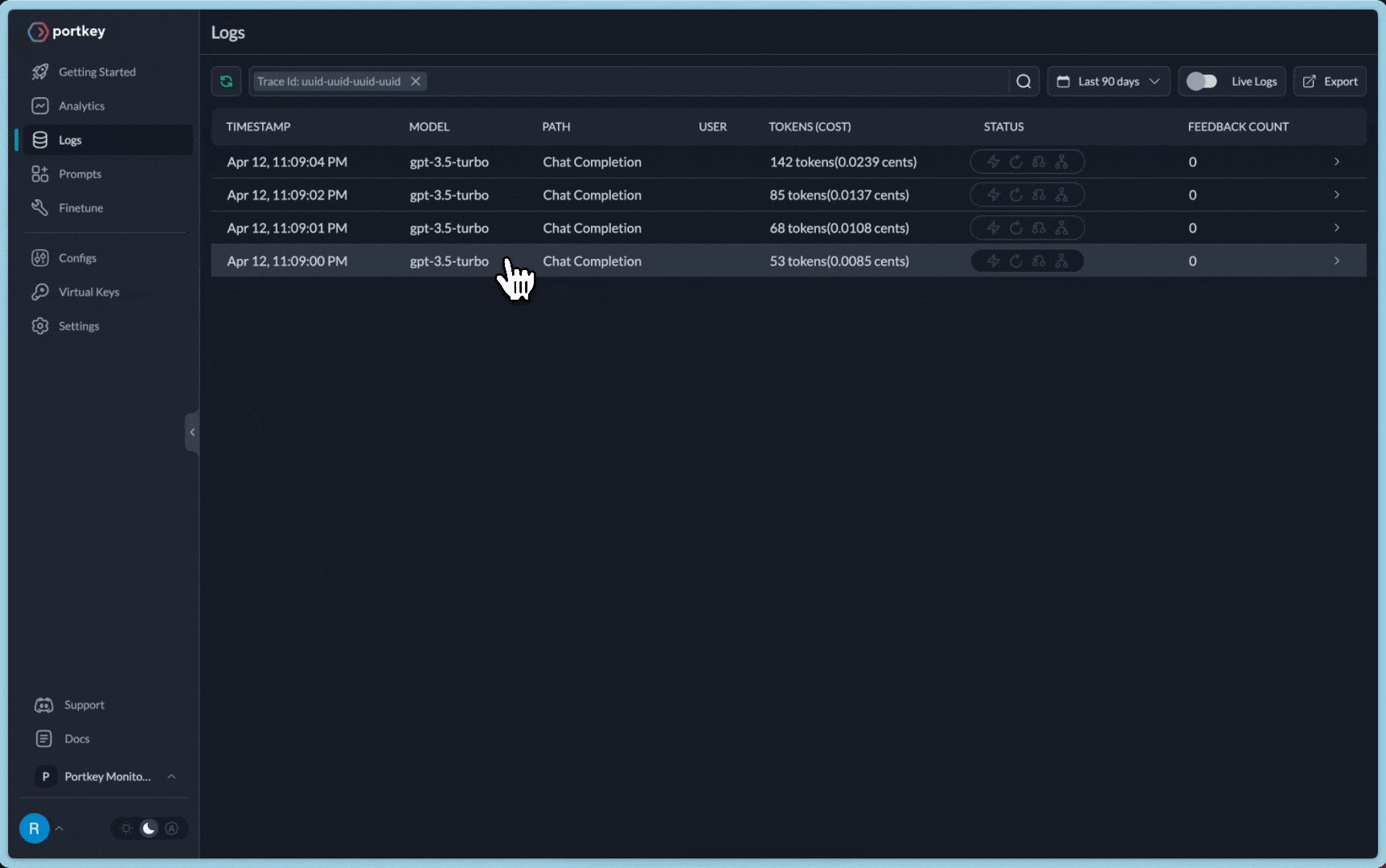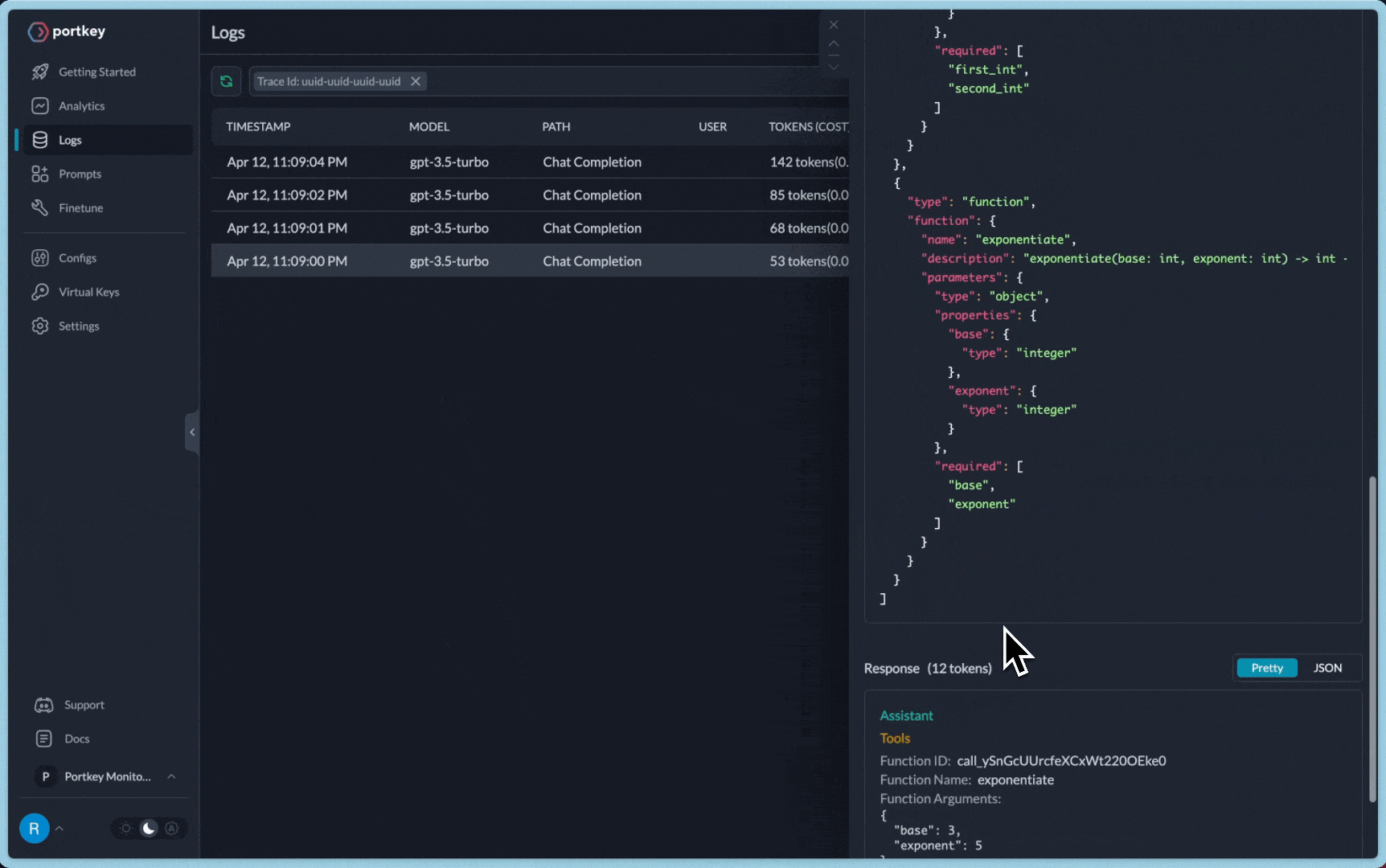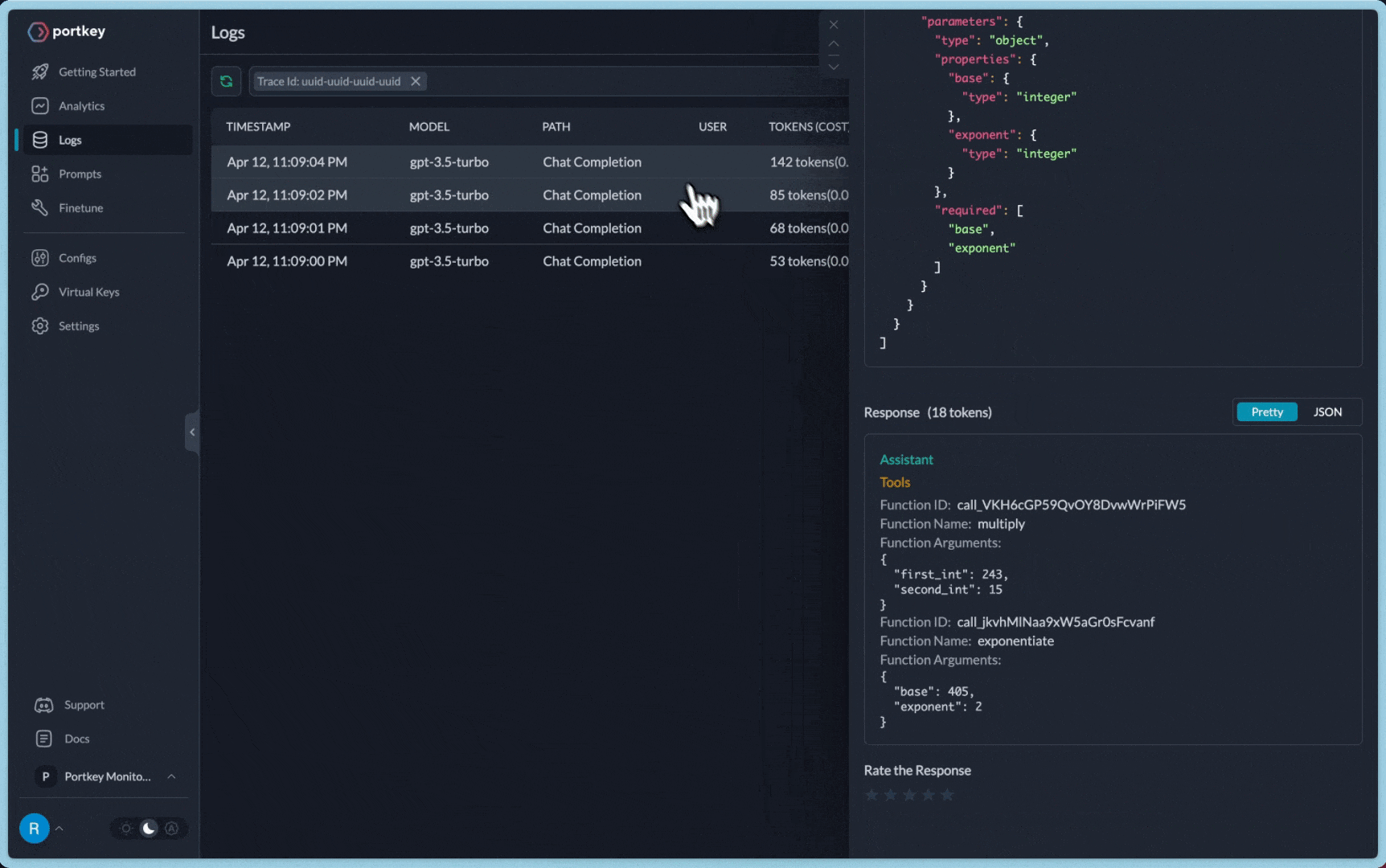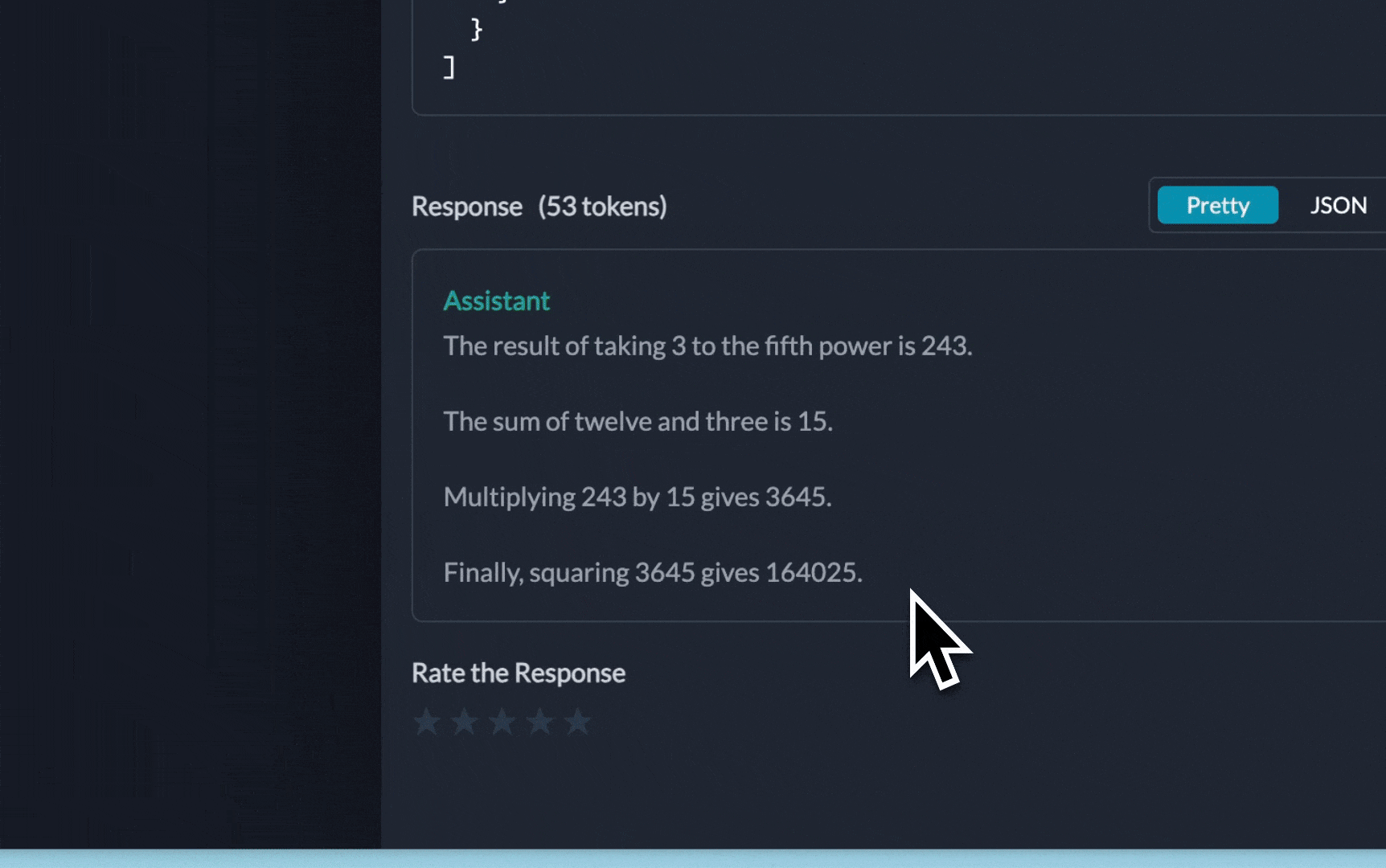
Additional Docs are available here:
- Observability - https://portkey.ai/docs/product/observability-modern-monitoring-for-llms
- AI Gateway - https://portkey.ai/docs/product/ai-gateway-streamline-llm-integrations
- Prompt Library - https://portkey.ai/docs/product/prompt-library
You can check out our popular Open Source AI Gateway here - https://github.com/portkey-ai/gateway
For detailed information on each feature and how to use it, please refer to the Portkey docs. If you have any questions or need further assistance, reach out to us on Twitter. or our support email.